DeepSeek的稀疏注意力机制

前面我们说在人工智能的进化史上,Transformer 就是那台伟大的“蒸汽机”,但随着模型规模的疯狂扩张,这台机器正面临一个巨大的问题:它太费电、太占地儿了。
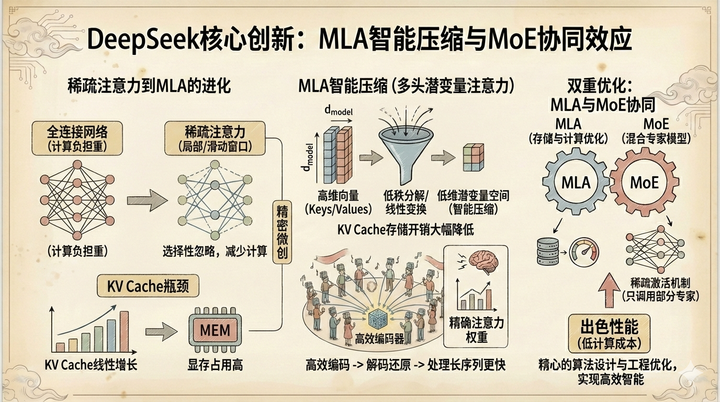
在标准的 Transformer 架构中,注意力机制遵循的是一种“全量链接”逻辑,在一句话中,每个词都要和剩下的词算一次关联度。例如,在一个有10个词的句子中,每个词都要和剩下的9个算一次关联,当100个词,一万个词,甚至上亿个词的时候,它的计算量是指数级增长的。
举个生活中的例子。想象一下,你在参加一个千人派对,为了听懂每句话,你必须同时盯着在场的每一个人的眼神、动作和语气。当派对人数从 10 个人增加到 1 万个人时,你需要消耗的脑力不是增加了一千倍,而是呈平方级爆炸。这种每一个词都要和所有词“深情对望”的模式,在技术上被称为自注意力机制(Self-Attention)。
稀疏注意力
为了打破这种效率瓶颈,科学家们提出了稀疏注意力机制(Sparse Attention)。它的核心逻辑非常简单:在那个万人的派对上,你真的有必要同时盯着每一个人吗?显然不需要。你可能只需要关注离你最近的几个人,或者只关注那些大声说话的“领头羊”就可以了。
稀疏注意力不再要求计算所有词语之间的关联度,而是通过某种规则,只让一部分词语产生“互动”。比如,每个词只看自己周围的邻居(局部注意力),或者按照某种模式间隔性地、选择性地关注部分词语(滑动窗口注意力、块稀疏注意力等)。这种做法把原来密不透风的“全连接网络”变成了像渔网一样有孔洞的结构,极大地减轻了计算负担,让 AI 在处理超长文章时不再因为内存崩溃而罢工。
DeepSeek 采用的就是这种思路,但 DeepSeek 的开发者把这个方案发挥得更加极致。他们意识到,如果单纯地“漏掉”一些连接虽然省事,但可能会丢掉重要的上下文细节。于是,他们不仅在计算上做减法,更在“记忆存储”上做了一次精密的微创手术。
在大模型运行的过程中,最占空间的东西叫作 KV Cache(键值缓存)。你可以把它理解为模型在处理序列时需要存储的中间计算结果——每一层的 Keys 和 Values 向量。随着序列长度增加,这些缓存会线性增长,迅速塞满昂贵的显卡显存。传统的稀疏注意力只是减少了计算量,而 DeepSeek 想要的是一种更高效的信息压缩和存储方式。
多头潜变量注意力
这就引出了 DeepSeek 最具创新性的技术:MLA(Multi-head Latent Attention,多头潜变量注意力)。从稀疏注意力到 MLA 的跨越,本质上是从“选择性忽略”进化到了“智能压缩”。在传统的注意力机制中,每个 token 的 Keys 和 Values 向量维度是固定的(通常为 dmodel),而 MLA 的做法是,通过线性变换或低秩分解等技术,将这些高维向量压缩到更低维的潜变量空间。
我们可以这样理解 MLA 的核心思想:它不再是在派对上随机挑选几个人去听,而是给每个参与者分配一个高效的编码器。虽然存储的数据量大幅减少,但通过精心设计的解码器,MLA 能够从压缩的信息中还原出足够精确的注意力权重。
这种低秩表示的技术,让 DeepSeek 在保持建模能力的同时,将 KV Cache 的存储开销降低到传统方法的几分之一甚至更低。这意味着在同样的硬件条件下,DeepSeek 可以比其他模型处理长得多的序列,而且生成速度更快。
在 DeepSeek 的模型架构里,这种“压缩后的注意力”还与 MoE(Mixture of Experts,混合专家模型) 形成了良好的协同效应。MoE 通过稀疏激活机制,在推理时只调用部分专家网络,从而减少计算量;而 MLA 则在注意力层面实现了存储和计算的优化。
这种双重的效率优化策略,正是 DeepSeek 能够以相对较低的计算成本获得出色性能的关键所在。它证明了 AI 的发展不一定非要依赖无限的算力投入,精心的算法设计和工程优化同样能够产生强大的智能。
从早期的全注意力,到后来的各种稀疏注意力变体,再到 DeepSeek 基于压缩潜变量的注意力机制,我们能看到 AI 正在逐步学会如何更加高效地处理信息。人类大脑也从来不会同时激活所有神经元,而是通过某种高效的编码和选择机制,从海量信息中提取关键特征。
MLA 这类技术的出现,标志着大模型正在逐步摆脱对算力的过度依赖,变得更加实用和高效。这种对注意力机制的持续优化和创新,是推动大语言模型技术向前发展的重要方向。