Transformer核心原理
 如果我们把当今席卷全球的人工智能热潮比作一场工业革命,那么 Transformer 就是那台最核心的蒸汽机。在 2017 年之前,人工智能虽然也在进步,但它理解人类语言的方式存在效率瓶颈。那时候的主流技术叫做 RNN(循环神经网络)。我们可以把 RNN 想象成一个手里拿着放大镜、必须顺着句子一个字一个字往后挪着读的学生。
如果我们把当今席卷全球的人工智能热潮比作一场工业革命,那么 Transformer 就是那台最核心的蒸汽机。在 2017 年之前,人工智能虽然也在进步,但它理解人类语言的方式存在效率瓶颈。那时候的主流技术叫做 RNN(循环神经网络)。我们可以把 RNN 想象成一个手里拿着放大镜、必须顺着句子一个字一个字往后挪着读的学生。
这种方式有一个致命的缺陷:如果句子太长,这个学生读到句尾的时候,往往就把句首的内容给忘干净了。而且,因为它必须按时间步顺序计算,前面时间步计算完才能进行下一步,这导致它的工作效率非常低下,难以处理超大规模的数据。
就在 2017 年,谷歌的研究团队发表了一篇具有里程碑意义的论文,名字非常有力量:《Attention Is All You Need》,翻译成中文就是"注意力就是你所需要的一切"。论文中正式向世界推出了 Transformer 模型,彻底颠覆了传统的人工智能训练方法。它不再像 RNN 那样排队阅读,而是像一个拥有"上帝视角"的超级扫描仪,能够宏观地、瞬间扫描一整段甚至一整本书的文字。这种并行处理的能力让它的速度实现了质的飞跃,而它之所以能看得又快又准,全靠它内部那个天才的设计——注意力机制。
注意力机制
什么是注意力机制?接下来我们就深入剖析一下它的内在逻辑。在 Transformer 的世界里,它会给每一个词都赋予三个极具逻辑性的角色,分别是 Q、K、V。
听起来很高端,但其实很简单。Q 就是 Query,代表某个词发出的"查询向量",它在问:我需要找什么样的信息来完善我的含义?K 则是 Key,代表某个词的"键向量",它在告诉别人:我是一个什么样的位置,我能提供什么信息。而 V 表示 Value,它是某个词的"值向量",包含了这个词在当前上下文中最有效的信息。
我们可以拿一个简单的句子"苹果很好吃"来实战演练一遍。当把这句话扔给 Transformer 学习时,它首先会把这句话拆解成不同的词,然后为每个词生成属于它们自己的 Q、K、V。假设我们现在要计算"苹果"这个词在这一句语境下的真正含义,Transformer 会按照三个非常严谨的步骤来执行。
第一步是匹配。 这就好比是一场大型的"连连看"或者"相亲会"。"苹果"这个词会带着它的 Q,也就是它的"查询向量",去句子里寻找跟它相匹配的 K,也就是和句子里的每个词的"键向量"进行比对。首先,它会去匹配它自己,因为"苹果"最懂"苹果",所以匹配度非常高。接着,它会去匹配"很好吃"这个词。在它的知识库里,它知道"苹果"是一种食物,而"好吃"是形容食物的,所以这两者之间的关联度也很强。通过这一步,系统就发现了词与词之间的逻辑纽带。
第二步是打分和算权重。 这里涉及一个数学上的细节。当我们算出来"苹果"和自己的匹配度很高,和"很好吃"的匹配度也很强的时候,系统不能直接使用这些原始数字。在 Transformer 的内部,它有一个专门的数学步骤叫做 softmax 函数,会把所有的匹配分数进行归一化处理。这意味着,不管一句话里有多少个词,它们最后分到的注意力权重加起来必须刚好等于百分之百。
这就像是一个有限的精力分配过程。比如在"苹果很好吃"这句话里,系统可能会给"苹果"自己分配相对较高的注意力权重,给"很好吃"分配显著的注意力权重。这种基于相关性自动计算的打分方式让 AI 能够像人类一样,在海量信息中瞬间抓住重点。
第三步是融合并提取 V。 这一步是见证奇迹的时刻。系统会根据第二步算出来的权重比例,把各个词的 V,也就是它们的"值向量"提取出来并加权混合。就好比我们在调配一杯果汁。"苹果"这个词提供了主要的味道基础,同时它又吸取了"很好吃"这个词提供的美味精华。最终,系统得出的"苹果"不再是词典里那个干巴巴的、孤立的水果名词,而是一个在当前语境下具有完整语义的概念。
这种方法不再是简单地记录一个词。传统的 AI 可能会记录"苹果是一个名词",但 Transformer 是在每一句话里都重新给"苹果"赋予上下文相关的含义。如果在另一句话里说"苹果手机很贵",那么通过这三个步骤,此时的"苹果"就会去重点匹配"手机"和"贵"的语义信息,最后融合出来的含义就变成了一家科技公司的电子产品。这种根据上下文实时调整含义的能力,就是大模型之所以能像真人一样交流的秘密所在。
当然,真实的 Transformer 模型比这还要更复杂一点点。为了从不同角度捕捉语义信息,科学家们给它设计了 "多头注意力"机制。我们可以把它想象成有多个不同的"注意力头"同时在看"苹果很好吃"这句话。每个注意力头学习不同的语义模式:第一个头可能关注主语和谓语的关系,第二个头可能关注形容词的修饰作用,第三个头可能关注整体的语义连贯性等。最后,这些不同头观察到的语义信息会被汇总在一起,形成一个更加丰富和立体的理解。这种多角度的观察,让 AI 对语言的理解达到了前所未有的深度。

编码器和解码器
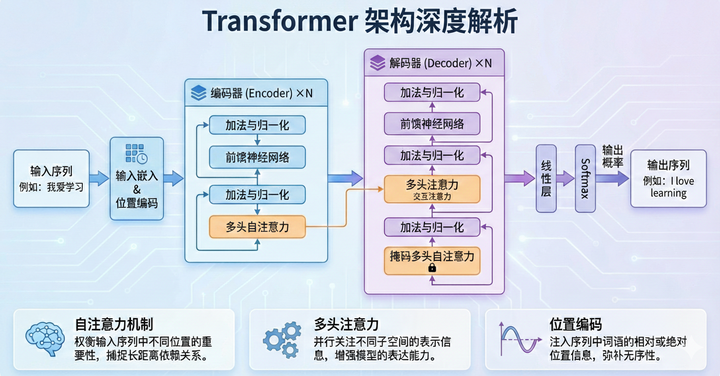
在 Transformer 的整体结构中,有两个核心组件:编码器和解码器。编码器就像是一个博览群书的学者,利用注意力机制,把输入的文字打碎、重组、理解,最后转化成一种极其复杂的数学表达,也就是它"吃透"了这句话的意思。而解码器则像是一个才华横溢的作家,它根据编码器的理解结果,再加上它之前已经生成的文本,不断地预测下一个最可能的词。
我们现在常说的 GPT,全称是 Generative Pre-trained Transformer,意思是"生成式预训练 Transformer"。它本质上是一个纯解码器架构的模型。它通过在互联网上阅读数以亿计的文本,学会了这种 Q、K、V 的匹配逻辑。所以当你问它问题时,它并不是在翻字典找答案,而是利用注意力机制,在它浩如烟海的知识库里进行瞬间的权重计算,从而预测出最合理的下一个词和整段回答。
这种技术的发布不仅改变了聊天机器人,而且也启发了科学家们对多媒体数据的处理。他们发现既然文字可以用这种"全景扫描"和"打分融合"的方式处理,那么图像、声音甚至蛋白质的分子结构是不是也可以呢?答案是肯定的。现在最先进的 AI 绘画工具和音频生成工具,底层几乎都流淌着 Transformer 的血液。它已经成为了一门能够处理世间万物的通用框架。
总结
总结一下,Transformer 的天才之处就在于它看待序列信息的方式。它不再受限于元素出现的先后顺序(虽然通过位置编码保留了顺序信息),而是通过 QKV 的匹配逻辑,让每一个元素都能和全篇的元素进行信息交互。它让机器真正学会了什么是"上下文依赖",什么是"重点关注"。正如那篇著名的论文标题所言,它证明了在深度学习的领域里,只要你的注意力机制设计得足够精妙,你就能模拟出接近人类的语言理解能力。
这就是 Transformer 的核心逻辑。它是一场关于"注意力分配"的数学革命,它把离散的符号变成了流动的、有生命力的信息流。理解了权重计算以及特征表示的动态调整,就能理解这个时代最强大的大脑是如何运转的。它不仅仅是一个神经网络架构,更是一套模拟人类认知深度学习的精密系统,正带着我们走向一个全新的智能时代。
Attention Is All You Need论文:https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
https://proceedings.neurips.cc/paper\\_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf | https://proceedings.neurips.cc/paper\_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf