普通人都应该懂的AI核心概念与底层原理
 本文将重点介绍AI技术领域的核心概念与底层原理,力求让普通人和技术人员都能理解。
本文将重点介绍AI技术领域的核心概念与底层原理,力求让普通人和技术人员都能理解。
首先,我们来介绍AI领域常见的缩写和专业词汇。我会用"人话"来解析它们,这些内容虽然基础,但理解它们至关重要。

LLM
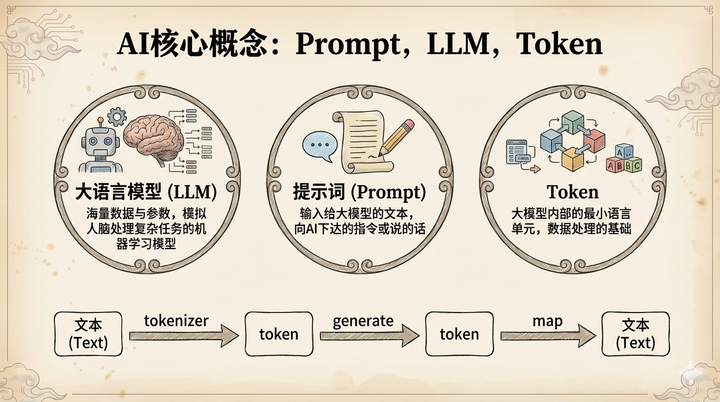
先说LLM,它是Large Language Model的缩写,即大语言模型,也就是我们常说的大模型。简单来说,什么是大语言模型?大指的是数据量大和参数量大。大语言模型通常由海量文本数据训练而成,这些数据可能包括书籍、网页、文章、对话等。而参数量大,指的是模型通过庞大数据训练得到的数值,这些参数决定了模型如何处理和生成语言。如今的大模型通常包含数十亿、数百亿甚至数千亿以上的参数。
第二个词是语言,指的是大模型能够处理人类的自然语言。这包括文本理解,例如理解句子含义和上下文关系;也包括文本生成,即根据输入生成相应文本,如回答问题或写文章;还包括语法和语义分析,处理语言中的语法规则、词义以及句子结构。
最后是模型,它指的是一种通过数学和算法构建的系统,能够模拟人脑来解决各种复杂任务。
总结来说,"大语言模型"就是一个利用海量数据和参数,通过深度学习技术来处理与生成自然语言的机器学习模型,它可以模拟人脑处理各种复杂任务。
Prompt
说完LLM,再来讲一下Prompt,中文叫提示词。简单说,这就是我们输入给大模型的文本内容,可以理解为你跟大模型说的话或下达的指令。提示词的质量,很大程度上决定了大模型回答的质量。这里想多说一句,未来孩子学好语文绝对至关重要。语文学不好,就无法清晰地表达自己的想法,以后甚至连AI都指挥不好。
Token
接下来是Token。简单说,Token是大模型内部使用的语言体系。举个例子,人类有不同的语言,大模型也一样,它也有自己的语言。当我们发送文本给大模型时,它会先将文本转换成自己的语言,推理生成答案后,再翻译成我们能懂的语言输出。正如人类语言有最小的字词单元(汉语的字/词,英语的字母/单词),大模型语言体系中的最小单元就称为Token。
这种从人类语言到大模型语言的翻译规则,也是由人类定义的。以中文为例,由于不同厂商的大模型采用了不同的文本切分方法,一个 Token 对应的汉字数量会有所不同,但通常情况下,1 Token 约等于 1-2 个汉字。目前大模型的收费计算方式,以及对输入输出长度的限制,都是以 Token 为单位的。
Context
另一个我们经常听到的概念是上下文,英文是 Context,指的是对话前后的信息。由此还衍生出两个概念:上下文长度和上下文窗口。上下文长度,指的是和大模型一次交互所能处理的最大 Token 数量;而上下文窗口,指的是大模型在生成每个 Token 时,实际参考的前面内容的范围。在大多数情况下,这两个概念实际上指的是同一个概念,即模型能够处理的最大Token数量限制。
关于上下文窗口的概念,我再深入讲解一下。如果能理解更好,不能理解也没关系,这完全不影响你使用 AI 工具以及后续的 AI 开发。
要理解上下文窗口,就得从 GPT 这三个字母说起。我第一次听到 GPT 这个词是在 2022 年 11 月 30 日 ChatGPT 发布的时候。ChatGPT 其实是两个词,一个是 chat,这个好理解,就是聊天。重点是 GPT,那什么是 GPT 呢?翻译过来就是 Generative Pre-trained Transformer,中文叫生成式预训练转换器。我们来挨个解析一下。
 首先是生成式(Generative):所谓生成式,指的是大模型以已有的输入为基础,不断计算并生成下一个字词(Token),从而逐字完成回答的过程。这个过程,很像一个单字接龙的游戏。我们用一个例子来模拟一下这个过程。
首先是生成式(Generative):所谓生成式,指的是大模型以已有的输入为基础,不断计算并生成下一个字词(Token),从而逐字完成回答的过程。这个过程,很像一个单字接龙的游戏。我们用一个例子来模拟一下这个过程。
1.我们首先给大模型一个提示词(Prompt),为了简化,这里只用一个单词:How。
2.接着,大模型会结合其"大脑中存储的知识"进行计算推理,判断出"How"后面接"are"这个词的概率最大,于是输出"are"。
3.在已知"How are"的情况下,大模型再次推理计算,判断出"How are"后面接"you"的概率最大,于是输出"you"。
4.这个过程会不断重复。每次大模型都会基于已有的输入和已生成的内容,计算下一个最可能的词(Token),并将新的输出加入到上下文窗口中。
5.直到计算出下一个词是 [end of text] 的概率最大时,输出便会终止,对话结束([end of text] 是一个特殊的 Token,用于标记对话的结束)。
 这就是大语言模型真实的工作逻辑。它看似很厉害,实际上就是在玩"单字接龙"游戏。而前面提到的"上下文窗口",指的就是在生成过程中,大模型能够参考和处理的上下文信息的最大Token数量范围。
这就是大语言模型真实的工作逻辑。它看似很厉害,实际上就是在玩"单字接龙"游戏。而前面提到的"上下文窗口",指的就是在生成过程中,大模型能够参考和处理的上下文信息的最大Token数量范围。
说完"生成式",再来说预训练(Pre-trained)。所谓预训练,就是大模型预先学习并将对知识的理解存储在"大脑"里的过程。这跟人类很像,人的大脑也无法理解自己从未见过或学习过的知识,所以需要预先学习。
不过,对于机器而言,预训练过程需要耗费大量的时间和算力资源。当你了解预训练机制后,就会明白,在没有外部帮助(例如使用浏览器插件、RAG 等技术)的情况下,大模型所掌握的知识总是不完备的,并且是滞后的(非实时的)。
那么,在预训练阶段,大模型究竟学了什么,又学了多少呢?以 GPT-3 为例,它的训练数据集包含了 4990 亿个 Token(约 570 GB 文本),这些数据主要来源于高质量的网页、书籍数据库和维基百科等。你可能对 4990 亿这个数字没什么概念,我们不妨做个换算:如果按照平均每个中文字符对应1.5个Token来估算,这大约相当于13亿个中文字符。对于一部长篇小说(约200万字)来说,这相当于6500部小说的文本量。这个规模虽然庞大,但远非之前计算的几十万本书那么夸张。
Transformer
最后是转换器(Transformer)。这是一个比较专业的技术词汇,简单来说,它是一种基于自注意力机制处理文本内容的模型架构,你大概知道这个概念就行。后续我会对它进行深入讲解,并带大家自己动手实现一个简化版的 Transformer。
好了,讲完前面这些,再简单提几个你可能听得比较少的概念:泛化能力、多模态和对齐能力。这几个概念就不展开细说了,简单理解一下即可。
首先是泛化能力。用专业术语说,它指的是大模型在未曾见过的数据上表现出良好理解的能力;换成大白话,就是"举一反三"的能力。人类就是泛化能力很强的物种,我们不需要见过世界上每一只猫,就能认识"猫"这个概念。
其次是多模态,指的是多种数据类型的交互,从而能够提供更接近人类感知的场景。正如人有眼、耳、鼻、舌、身、意等多种感知模态,大模型对应的模态则是文本、图像、音频、视频等。
最后是对齐能力,指的是与人类价值观和利益目标保持一致的能力。大模型相比我们普通个体可以说是"无所不知",但它并不会把它知道的一切都告诉你。例如,你问 ChatGPT 如何制造炸弹,它虽然知道,但不会告诉你具体步骤和配方,这是因为 ChatGPT 做了很好的对齐工程。不过,目前有很多提示词注入的方法可以绕过各种限制,这也开辟了大模型领域安全对抗的新战场(事实上,人类自身也并非一个价值观完全对齐的物种,同一件事在一些群体眼中稀松平常,在另一些群体眼中却十恶不赦,因此"和谁对齐"确实是一个灵魂问题)。
以上就是 AI 领域一些常见的核心概念。理解这些,能帮助你更好地使用 AI 工具,并投入到后续的 AI 应用开发中。