盘点国内外主流大模型

前两篇文章梳理了人工智能的发展史和细分领域,相信大家对AI有了基本认知。接下来,我们聚焦当下,聊聊生成式AI的重要基础技术——大模型,并为大家科普一下国内外大模型领域的“当红炸子鸡”。本文介绍的都是当前主流的通用大模型,对于国内众多垂直领域的大模型,也会用几张图简单介绍。
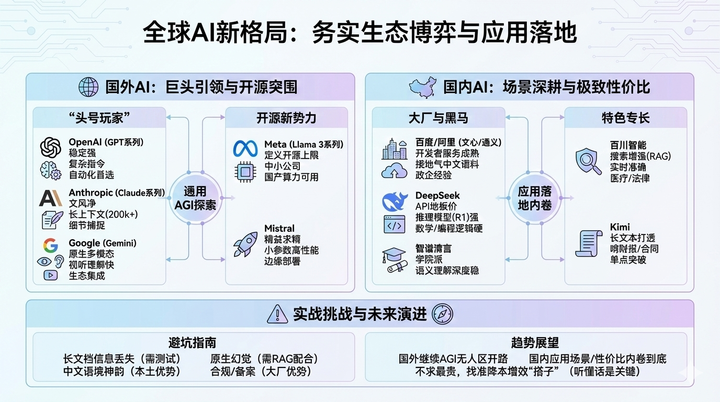
如今的AI领域,早已过了仅靠几个PPT就能唬人的阶段。大模型已从实验室的“玩具”转变为生产线的“发动机”。若你站在技术选型或行业观察者的视角审视全球AI版图,会发现这不再是一场单纯的参数竞赛,而是一场极其务实的生态博弈。
国外大模型
先聊聊国外的“头号玩家”。OpenAI的GPT系列,尤其是GPT-4o及其衍生版本,依然是许多开发者心中的底牌。它的强大在于“稳”,这种稳定性体现在处理极其复杂的逻辑指令时,很少“掉链子”。如果你要构建高度自动化的系统,GPT依然是首选。
有趣的是,Anthropic的Claude系列如今已成为许多文字工作者和编程高手的“白月光”。Claude的优势在于文风更干净,没有浓重的AI翻译腔,而且其200k甚至更长的上下文处理能力非常扎实。许多产品经理反馈,在处理长达数百页的行业研报时,Claude捕捉细节的能力甚至比GPT更细腻。
至于Google的Gemini,其杀手锏是原生多模态能力,简单说就是理解视频、音频的速度极快,并且背靠Google全家桶,这种生态集成能力是其他两家难以比拟的。
当然,如果你不想被大厂的API调用费“割韭菜”,或者对数据隐私有洁癖,开源界绝对是你的救命稻草。Meta发布的Llama 3系列几乎定义了开源模型的上限,它让很多中小公司也能在自己的4090显卡或国产算力卡上跑起顶尖的智能。而来自法国的Mistral则走“精益求精”路线,它用极小的参数实现了跨级的性能,对于那些追求推理速度、想在边缘侧部署的开发者来说,简直是神作。
国内大模型
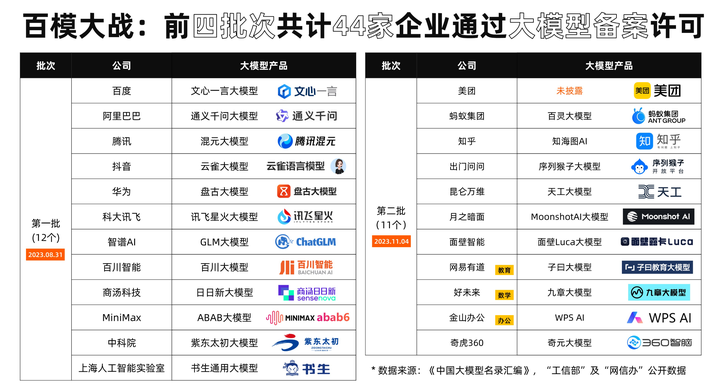
镜头转回国内,这里的“百模大战”已经打到了骨子里。以前大家爱比谁的参数大,现在大家都在比谁能落地、谁更省钱。文心一言和通义千问这类大厂出品,最强的地方不在于模型本身有多么惊艳,而在于它们背后那套成熟的开发者服务体系和极其接地气的中文语料储备。说白了,处理中国特有的那种含蓄、多义的政企公文,大厂模型确实更有“经验”。

但这两年真正让人眼前一亮的是DeepSeek。这匹黑马不仅把API价格打到了地板上,更在推理模型(比如R1系列)上展现了极其恐怖的逻辑能力。
现在很多做代码助手的团队,首选往往不是国外的模型,而是DeepSeek,因为它在数学和编程逻辑上确实做得够硬。
智谱清言则更像一个“学院派高手”,在语义理解的深度上非常稳。百川智能则把搜索增强(RAG)玩得很透,它回答问题的实时性和准确率在医疗、法律这类严谨领域很吃香。
至于Kimi,它其实是把“长文本”这一个点打透了,很多职场人用它来“啃”财报和合同,这种单点突破的策略在产品化路径上走得非常聪明。
不过,测评跑分终究是实验室里的数据,实战中到处是坑。比如,很多模型号称支持100万Token的上下文,但在实际测试中,一旦文档超过10万字,就容易出现“中间信息丢失”的现象。
GPT-4o表现比较均衡,而Claude和国内的Kimi在这种“大海捞针”测试中通常能拿更高分。再比如,中文语境里的那些梗和冷笑话,国外模型哪怕翻译对了字面意思,也往往抓不住那个“神韵”,这时候国内模型的本土优势就显现出来了。
对于开发者和产品经理来说,选型最怕的就是“杀鸡用牛刀”。做一个简单的FAQ机器人,真没必要去调GPT-4o的接口,DeepSeek或者通义千问的轻量版模型不仅响应快,成本甚至能缩减到原来的十分之一。
实战中的另一个深坑是“原生幻觉”,不管模型多强,只要不配合知识库(RAG)做增强,它总会一本正经地胡说八道。此外,国内企业还要面对算力合规、算法备案这些硬指标,这时候选择智谱或者文心这种背景深厚的模型,能省掉很多法务和合规上的麻烦。
往后看,AI版图的演进大概率会分化成两条线:国外继续在通用人工智能(AGI)的无人区开路,而国内则会在应用场景和性价比上把内卷进行到底。选模型不需要追求最贵,关键看它能不能在你的业务场景里“听懂话”。是看中Claude那种温润如玉的交流感,还是DeepSeek那种极致的推理性价比,或者是Kimi那种处理海量资料的耐心?在这个技术迭代按周计算的时代,与其追求全能,不如找准那个最能帮你降本增效的“搭子”。